

The meteoric rise in the value of bitcoins has put a spotlight on the blockchain, which is the primary public, digital ledger for bitcoin transactions. A blockchain allows digital transactions to be transparent and distributed, but not copied. It is thought to be the brainchild of an anonymous person or group operating under the pseudonym Satoshi Nakamoto.
The bitcoin network has attracted attention from almost all industries and experts due to its variable market value. These captains of industry and the experts are trying to figure out how this technology can be adapted to and integrated with their work. The dictionary definition of blockchain is, “A digital ledger in which transactions made in bitcoin or another cryptocurrency are recorded chronologically and publicly.” This definition is derived from the most popular implementation of blockchain technology — the bitcoin. But blockchain is actually not bitcoin. Let’s have a look at blockchain technology, in general.
Distributed ledger technology (DLT)
Distributed ledger technology includes blockchain technologies and smart contracts. While DLT existed prior to bitcoin or blockchain, it marks the convergence of a host of technologies, including the time-stamping of transactions, peer-to-peer (P2P) networks, cryptography, shared computational power, as well as a new consensus algorithm. In short, distributed ledger technology is generally made up of three basic components:
- A data model that captures the current state of the ledger.
- A language of transactions that changes the ledger state.
- A protocol used to build consensus among participants around which transactions will be accepted by the ledger and in what order.
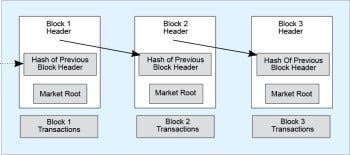
Figure 1: Structure of a block in the chain
What is blockchain technology?
Blockchain is a specific form or sub-set of distributed ledger technologies, which constructs a chronological chain of blocks; hence the name ‘blockchain’. A block refers to a set of transactions that is bundled together and added to the chain at the same time. A blockchain is a peer-to-peer distributed ledger, forged by consensus, combined with a system for smart contracts and other assistive technologies. Together, these can be used to build a new generation of transactional applications that establish trust, accountability and transparency at their core, while streamlining business processes and legal constraints. The blockchain then tracks various assets, the transactions are grouped into blocks, and there can be any number of transactions per block. A block commonly consists of the following four pieces of metadata:
- The reference to the previous block
- The proof of work, also known as a nonce
- The time-stamp
- The Merkle tree root for the transactions included in this block
Is a blockchain similar to a database?
Blockchain technology is different from databases in some key aspects. In a relational database, data can be easily modified or deleted. Typically, there are database administrators who may make changes to any part of the data or its structure and even to relational databases. A blockchain, however, is a write-only data structure, where new entries get appended onto the end of the ledger. There are no administrator permissions within a blockchain that allow the editing or deleting of data. Also, the relational databases were originally designed for centralised applications, where a single entity controls the data. In contrast, blockchains were specifically designed for decentralised applications.
Types of blockchains
A blockchain can be both permissionless (e.g., bitcoin and Ethereum) or permissioned, like the different Hyperledger blockchain frameworks. The choice between permissionless and permissioned blockchains is driven by the particular use case.
A permissionless blockchain is also known as a public blockchain, because anyone can join the network. A permissioned blockchain, or private blockchain, requires pre-verification of the participants within the network, who are usually known to each other.
Characteristics of blockchains
Here is a list of some of the well-known properties
of blockchains.
The immutability of the data which sits on the blockchain is perhaps the most powerful and convincing reason to deploy blockchain-based solutions for a variety of socio-economic processes that are currently recorded on centralised servers. This ‘unchanging over time’ feature makes the blockchain useful for accounting and financial transactions, in identity management and in asset ownership, management and transfer, just to name a few examples. Once a transaction is written onto the blockchain, no one can change it or, at least, it would be extremely difficult to do so.
Transparency of data is embedded within the network as a whole. The blockchain network exists in a state of consensus, one that automatically checks in with itself. Due to the structure of a block, the data in a blockchain cannot be corrupted; hence altering any unit of information in it is almost impossible. Though, in theory, this can be done by using a huge amount of computing power to override the entire network, this is not possible practically.
By design, the blockchain is a decentralised technology. Anything that happens on it is a function of the network, as a whole. A global network of computers uses blockchain technology to jointly manage the database that records transactions. The consensus mechanism discussed next ensures the correctness of data stored on the blockchain.
By storing data across its network, the blockchain eliminates the risks that come with data being held centrally, and the network lacks centralised points of vulnerability that are prone to being exploited. The blockchain ensures all participants in the network use encryption technologies for the security of the data. Primarily, it uses PKI (public key infrastructure), and it is up to the participants to select other encryption technologies as per their preference.
What are consensus mechanisms and the types of consensus algorithms?
Consensus is an agreement among the network peers; it refers to a system of ensuring that participants agree to a certain state of the system as the true state. It is a process whereby the peers synchronise the data on the blockchain. There are a number of consensus mechanisms or algorithms. One is Proof of Work. Others include Proof of Stake, Proof of Elapsed Time and Simplified Byzantine Fault Tolerance. Bitcoin and Ethereum use Proof of Work, though Ethereum is moving towards Proof of Stake.
What are smart contracts?
Back in 1996, a man named Nick Szabo coined the term ‘smart contract’. You can think of it as a computer protocol used to facilitate, verify, or enforce the negotiation of a legal contract. A smart contract is a phrase used to describe computer code. Smart contracts are simply computer programs that execute predefined actions when certain conditions within the system are met. Smart contracts provide the language of transactions that allows the ledger state to be modified. They can facilitate the exchange and transfer of anything of value (e.g., shares, money, content and property).
Open source blockchain frameworks, projects and communities
Looking at the current state of research and some of the implementations of blockchain technologies, we can certainly say that most enterprise blockchain initiatives are backed by open source projects. Here’s a list of some of the popular open source blockchain projects.
- Hyperledger is an open source effort created to advance cross-industry blockchain technologies. Hosted by the Linux Foundation, it is a global collaboration of members from various industries and organisations.
- Quorum is a permissioned implementation of Ethereum, which supports data privacy. Quorum achieves data privacy by allowing data visibility on a need-to-know basis, using a voting-based consensus algorithm. Interestingly, Quorum was created and open sourced by J.P. Morgan.
- Chain Core, created by chain.com, was initially designed for financial services institutions and for things like securities, bonds and currencies.
- Corda is a distributed ledger platform designed to record, manage and automate legal agreements between businesses. It was created by the R3 Company, which is a consortium of over a hundred global financial institutions.
Originally published at opensourceforu.com on June 2, 2018.


